Tabla I. Sintomas considerados en el core data set adaptado.
|
Categoría
|
Síntoma
|
Psicosocial
|
Ansiedad
|
Ataque de pánico
|
Depresión
|
Estrés
|
Dolor
|
Cefalea
|
Dolores articulares
|
Neuralgia trigeminal
|
Cognición
|
Queja de memoria
|
Déficit atencional
|
Afasia
|
Equilibrio
|
Trastorno del equilibrio
|
Mareos
|
Vértigo
|
Sensibilidad
|
Entumecimiento
|
Parestesias
|
Disestesias
|
Trastornos termoalgésicos
|
Fatiga
|
Fatiga
|
Visión
|
Visión borrosa
|
Visión doble
|
Ceguera parcial
|
Tracto urinario
|
Urgencia miccional
|
Trastorno esfinteriano
|
Disinergia
|
Intestino
|
Defecación involuntaria
|
Estreñimiento
|
Miembros superiores
|
Lateralización
|
Incoordinación
|
Temblor
|
Debilidad
|
Parálisis
|
Espasticidad
|
Rigidez
|
Calambres
|
Miembros inferiores
|
Debilidad
|
Parálisis
|
Caída del miembro
|
Trastorno de la marcha
|
Dificultad para hablar
|
|
Dificultad para tragar
|
|
Disfunción sexual
|
|
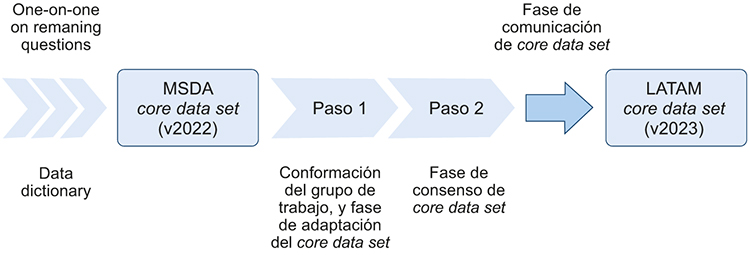
Fase de consenso del core data set
Una vez identificadas las variables de acceso recolectadas por los registros, como cobertura de salud, tiempo a la cobertura, nombre de tratamientos, etc., se registraron las variables y la forma de recolección de las variables de la categoría en el proceso de adaptación del
core data set. Para concretar el consenso se siguió la metodología Delphi remoto de ronda de cuestionarios y discusión a distancia de las variables del
core data set (escenarios) [
12-
14]. Operativamente se realizó una primera, una segunda y una tercera rondas (de ser necesario) de cuestionario vía virtual con los expertos en los que cada involucrado revisó el
data set adaptado. Se consultó sobre el grado de acuerdo de cada experto. Se recibió de cada experto la respuesta sobre cada variable y comentarios (de existir), y se vio el grado de acuerdo general sobre cada variable de ser parte del
data set (https://forms.gle/u9TmfVjrJTbKdiWE7), así como se evaluaron las observaciones generadas. Cada variable se analizó posteriormente de forma global entre todas las respuestas. Se estableció definir la presencia de acuerdo cuando el 70% de los encuestados respondía de forma homogénea; definir la incertidumbre cuando entre el 40 y el 70% respondían de forma homogénea; y definir el no acuerdo si menos del 40% respondía de forma homogénea. Los principales métodos estadísticos utilizados fueron medidas de tendencia central y dispersión: media, mediana, moda, máximo, mínimo y desviación estándar.
Fase de comunicación del core data set
Una vez formado el grupo metodológico y el grupo de expertos, llevado adelante el proceso de adaptación del
core data set y teniendo el documento local, se procedió a circularlo entre el grupo de trabajo para evaluar el consenso sobre cada una de las variables del
data set y determinar cuál quedaba en él.
Resultados
Un total de 23 neurólogos y dos metodólogos, que recibieron el protocolo y el proceso de implementación, aceptaron participar en el proyecto. Estos participantes provenían de Argentina (10), Brasil (tres), Colombia (uno), Costa Rica (uno), Chile (dos), Ecuador (dos), El Salvador (uno), Guatemala (uno), México (tres), Paraguay (uno), Panamá (uno), Perú (uno), República Dominicana (uno), Uruguay (uno) y Venezuela (uno). El desarrollo del proyecto tuvo lugar entre noviembre de 2022 y julio de 2023, y contó con la colaboración metodológica y logística de la MSDA. La estrategia de búsqueda utilizada identificó las variables de acceso que se incluyeron en el conjunto de datos básicos original creado previamente por la MSDA y que fueron traducidas en el proceso previo desarrollado (Fig. 2). Durante el proceso de consenso se llevaron a cabo dos rondas virtuales para que cada profesional evaluara las afirmaciones generadas. Una vez alcanzado el consenso en las afirmaciones, se llevó a cabo una tercera ronda virtual para generar comentarios y realizar una revisión final. Las diversas discusiones del grupo de trabajo condujeron al acuerdo sobre nueve categorías y 45 variables para el
core data set, versión 2023 para América Latina. Después de acordar las categorías, variables y valores, se finalizó el diccionario de datos del conjunto central de datos. Además, la categoría ‘acceso a la salud’ incorporada en el conjunto de datos básicos adaptado para América Latina consensuó la inclusión de tres variables, las cuales se detallan en las tablas I y II.
Figura 2. Resultados de la estrategia de búsqueda de variables de acceso.
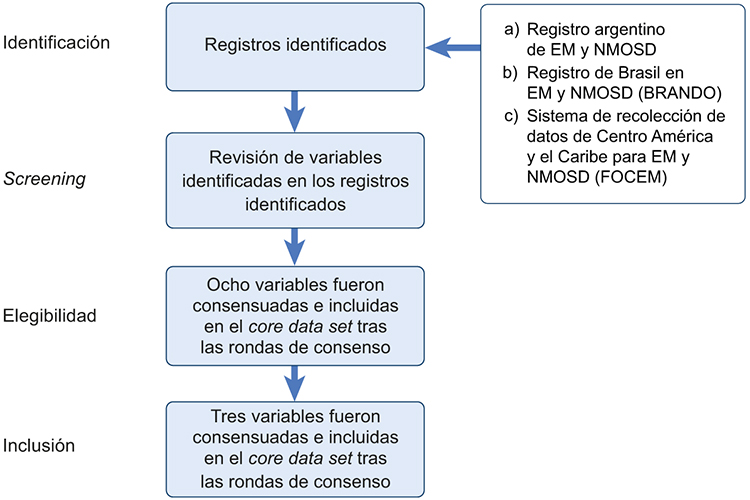
EM: esclerosis múltiple; NMOSD: trastorno del espectro de la neuromielitis óptica.
Tabla II. Comorbilidades consideradas en el core data set adaptado.
|
| |
Subcategoría
|
Abuso de alcohol
|
|
Autoinmune distinta de esclerosis múltiple
|
Espondilitis anquilosante
|
Diabetes de tipo I
|
Enfermedad inflamatoria intestinal
|
Miastenia grave
|
Psoriasis
|
Artritis reumatoide
|
Lupus eritematoso sistémico
|
Tiroiditis
|
Cáncer
|
Mama
|
Digestivo
|
Tiroideo
|
De vulva
|
Pulmón
|
Piel
|
Hematológico
|
Diabetes de tipo 2
|
|
Abuso de drogas
|
|
Epilepsia
|
|
Cataratas
|
|
Glaucoma
|
|
Degeneración macular
|
|
Fibromialgia
|
|
Psiquiátrica
|
Depresión
|
Psicosis
|
Ansiedad
|
Cardiovascular
|
Accidente cerebrovascular
|
Hiperlipidemia
|
Hipertensión
|
Isquemia cardíaca
|
Enfermedad vascular periférica
|
Arritmia cardíaca
|
Insuficiencia cardíaca congestiva
|
Respiratoria
|
Asma
|
Enfermedad pulmonar
|
Discusión
El objetivo primario del
core data set es el de reducir la heterogeneidad y promover la armonización entre las fuentes de datos en EM, reduciendo así el tiempo necesario para ejecutar esfuerzos en la recolección de datos de vida real y optimizar la colaboración global a gran escala [
5-
7].
En el presente trabajo logramos adaptar el
core data set creado globalmente (en prensa) al idioma español, identificamos las variables de acceso que tan importantes son en nuestro medio y que tanta relevancia tienen para ser homogeneizadas por los sistemas de recolección de datos, y en tercer lugar llegamos a un consenso con los principales involucrados en la generación y utilización de datos de vida real en EM en la región (Tabla III). Esto podría garantizar que el
core data set se implemente en los registros en vías de desarrollo y desarrollados con él a fin de armonizar la recolección de datos que la facilite y contribuya a la colaboración regional a gran escala [
5-
7].
Tabla III. Core data set adaptado y consensuado.
|
Categoría
|
Recolectado pora
|
Nombre de la variable
|
Nombre variable
|
Colección tiempo
|
Formato
|
SNOMED definición
|
SNOMED código
|
Valores de la variable
|
SNOMED término
|
SNOMED código
|
Categoría 1. Demografía
|
| |
A
|
Fecha de nacimiento
|
fecha_nac
|
PV
|
aaaa-mm-dd
|
Fecha de nacimiento
|
184099003
|
|
|
|
| |
A
|
Sexo (biológico)
|
sexo
|
PV
|
radio/select
|
Sexo biológico
|
734000001
|
Mujer
|
Mujer (hallazgo)
|
248152002
|
| |
|
|
|
|
|
|
|
Hombre
|
Hombre (hallazgo)
|
248153007
|
| |
A
|
País de residencia
|
residencia
|
PV, VS
|
lista
|
País de residencia
|
416647007
|
ISO 3166-1 (alpha-2)
|
-
|
-
|
| |
A
|
Ciudad de residencia
|
ciudad
|
PV, VS
|
lista
|
Ciudad de residencia
|
|
|
|
|
| |
A
|
Raza
|
raza
|
PV
|
lista
|
Raza observable
|
103579009
|
Blanco, negro, afro-americano, indo-americano, nativo de Alaska, asiático, nativo de Hawái u otras islas del Pacífico, desconocido, no seguro
|
Desconocido (valor calificativo)
|
261665006
|
| |
A
|
Etnia
|
etnia
|
PV
|
lista
|
Grupo étnico identificable clínicamente
|
397731000
|
Hispánico o latino, no hispánico o latino, desconocido, no seguro
|
|
|
| |
A
|
Nivel educativo
|
educación
|
PV
|
lista
|
Nivel educacional alcanzado
|
105421008
|
ISCED 0 = educación infantil;
ISCED 1 = educación primaria; ISCED 2 = educación secundaria inicial;
ISCED 3 = educación secundaria superior;
ISCED 4 = educación secundaria no terciaria; ISCED 5 = educación terciaria incompleta;
ISCED 6 = educación terciara completa;
ISCED 7 = educación universitaria;
ISCED 8 = educación doctoral o post universitaria
|
|
|
| |
A
|
Estado laboral
|
empleo
|
PV, VS
|
lista
|
Estado laboral en el momento de ser evaluado
|
224362002
|
Trabaja
|
|
224363007
|
Trabajo completo
|
|
160903007
|
Trabajo parcial
|
|
160904001
|
Estudiante
|
|
413327003
|
Retirado
|
|
105493001
|
Retirado por problema médico
|
|
160898008
|
Sin trabajo
|
|
73438004
|
Vive con sus padres
|
|
224457004 / 700149001
|
| |
A
|
Tabaquismo
|
fumador
|
PV, VS
|
radio/select
|
Tabaquismo en el momento de ser evaluado
|
|
Nunca fumo
|
|
266919005
|
Fumador actual
|
|
77176002
|
Fumó previamente
|
|
8517006
|
Desconoce
|
|
|
Categoría 2. Información sobre la historia de la enfermedad
|
| |
A
|
Fecha del diagnóstico
|
fecha_diagnostico
|
PV
|
aaaa-mm-dd
|
Fecha del diagnóstico
|
432213005
|
|
|
|
| |
A
|
Fecha de la primera recaída (inicio de la enfermedad)
|
fecha_inicio_enf
|
PV
|
aaaa-mm-dd
|
Fecha del comienzo de la enfermedad
|
298059007
|
|
|
|
| |
A
|
Curso de la EM
|
curso_EM
|
PV, VS
|
lista
|
Fenotipo de EM
|
24700007
|
Síndrome radiológico aislado
|
|
16415361000119105
|
Síndrome clínico aislado
|
|
445967004
|
EM recaída remisión
|
|
426373005
|
EM secundaria progresiva
|
|
425500002
|
EM primaria progresiva
|
|
428700003
|
Categoría 3. Información sobre el estado de la enfermedad
|
| |
A
|
Fecha de evaluación
|
fecha_evolución
|
PV, VS
|
aaaa-mm-dd
|
|
|
|
|
|
| |
N
|
Estado de la EM (neurólogo)
|
ms_status_clin
|
PV, VS
|
lista
|
Estado de la enfermedad desde la perspectiva del neurólogo
|
|
No activa y sin progresión; activa (RM activa o recaídas) y con progresión; activa pero sin progresión; no activa pero con progresión
|
|
|
| |
A
|
Síntomas actuales
|
sintomas_actuales
|
PV, VS, IR
|
casillas/
lista
|
|
|
(ver hoja ‘Síntomas’)
|
|
|
| |
N
|
Expanded disability status scale
|
edss_score
|
PV, VS, IR
|
flotante
|
Kurtzke multiple sclerosis rating scale (escala de valoración)
|
273554001
|
0, 1.0, 1.5... , 10
|
|
|
| |
N
|
25 Foot Walk Velocity Test
|
25fwt
|
PV, VS
|
flotante
|
|
|
(tiempo en segundos)
|
|
|
| |
N
|
9-Hole Peg Test
|
9hpt
|
PV, VS, IR
|
flotante
|
Puntuación en el 9-Hole Peg Test (entidad observable)
|
446602000
|
(tiempo en segundos,
mano dominante)
|
|
263557007
|
| |
N
|
Symbol Digit Modalities Test
|
sdmt
|
PV, VS
|
int
|
Puntuación en el Symbol Digit Modalities Test (entidad observable)
|
718387005
|
(número de respuestas correctas/sustituciones)
|
|
|
Categoría 4. Información sobre recaídas
|
| |
A
|
Tuvo recaídas
|
relapse
|
IR
|
boleano
|
Tuvo recaídas en el lapso de tiempo evaluado
|
230372003
|
Sí; no; no seguro
|
|
|
| |
A
|
Fecha de la recaída
|
fecha_recaida
|
IR
|
aaaa-mm-dd
|
|
|
|
|
|
| |
A
|
Usó corticoides en la recaída
|
corticoides_recaidas
|
IR
|
boleano
|
Tratamiento con corticosteroides y/o derivados de los corticosteroides (procedimiento)
|
788751009
|
Sí; no; desconozco
|
|
|
Categoría 5. Investigaciones paraclínicas
|
| |
A
|
Resonancia magnética hecha
|
RMI
|
VS
|
boolean
|
Resonancia magnética (procedimiento)
|
113091000
|
Sí; no
|
s. a.
|
|
| |
A
|
Región de la resonancia magnética realizada
|
RMI_region
|
VS
|
radio/select
|
|
|
Cerebro
|
|
816077007
|
Medula cervical
|
|
241646009
|
Medula dorsal
|
|
241647000
|
Medula completa
|
|
24164500800%
|
| |
A
|
Fecha de la resonancia magnética
|
fecha_mri
|
VS
|
aaaa-mm-dd
|
|
|
|
|
|
| |
N
|
Número de lesiones GAD+
|
mri_gd_les
|
VS
|
número entero
|
|
|
Número entero o desconocido
|
|
|
| |
N
|
Número de nuevas lesiones en FLAIR o T2
|
mri_new_les
|
VS
|
número entero
|
|
|
Número entero o desconocido
|
|
|
| |
N
|
Bandas oligoclonales presentes en el diagnóstico
|
BO_diagnostico
|
PV
|
boleano
|
Identificación de bandas oligoclonales en el líquido cefalorraquídeo y no en el suero en el momento del diagnóstico
|
113073005
|
Presentes; ausentes; no realizado; desconocido
|
|
|
Categoría 6. Comorbilidades e infecciones oportunistas
|
| |
A
|
Comorbilidades
|
comorb
|
PV, VS
|
boleano
|
Comorbilidades
|
398192003
|
Sí; no; desconoce
|
|
|
| |
A
|
Tipo de comorbilidad
|
tipo_comorbilidad
|
PV, VS
|
lista
|
|
|
(comorbilidades)
|
|
49601007
|
Cardiovascular
|
|
|
Respiratoria
|
|
50043002
|
Gastrointestinal
|
|
119292006
|
Psiquiatrica
|
|
74732009
|
Metabólica
|
|
75934005
|
Cáncer
|
|
86049000
|
Musculoesquelética
|
|
928000
|
Autoinmune distinta a EM
|
|
85828009
|
comorb list y subcategoria_solapa comorbidities
|
ver solapa
|
74964007
|
| |
A
|
Infección oportunista
|
infecc_opo
|
VS
|
boleano
|
Infección oportunista
|
61274003
|
Sí; no: desconoce
|
|
|
| |
A
|
Tipo de infección oportunista
|
tipo_infecc_opo
|
VS
|
lista
|
|
|
LMP; HSV;VZV; CMV; pneumocystis; canidiasis; criptococosis; listeriosis; HHV8; HHV6, otra; desconocida
|
|
|
| |
A
|
Fecha de infección oportunista
|
fecha_opo_infecc
|
VS
|
aaaa-mm-dd
|
|
|
|
|
|
| |
A
|
Resultado de la infección oportunista
|
opp_infec_out
|
VS
|
lista
|
|
|
En curso; recuperado con secuelas; recuperado sin secuelas; muerte
|
|
|
Categoría 7. Tratamientos modificadores de la enfermedad
|
| |
A
|
¿En tratamiento con DMT?
|
dmt_status
|
PV, VS
|
select/radio
|
|
|
Sí; no; paciente naive de tratamiento; desconoce
|
|
844585000
|
| |
A
|
Tipo de DMT
|
dmt_type
|
PV, VS
|
lista
|
|
|
Alemtuzumab
|
Alemtuzumab (fármaco)
|
129472003
|
Cladribina
|
Cladribina (fármaco)
|
386916009
|
Azatioprina
|
Azatioprina (fármaco)
|
372574004
|
Otro
|
Campo libre para pacientes en ensayos clínicos o recibiendo otros tratamientos
|
|
33
|
A
|
Fecha de inicio del tratamiento con DMT
|
dmt_start
|
PV, VS
|
aaaa-mm-dd
|
|
413946009
|
|
|
|
34
|
A
|
Fecha del fin del DMT
|
dmt_stop
|
PV, VS
|
aaaa-mm-dd
|
Fecha de interrupción de tratamiento
|
413947000
|
|
|
|
35
|
A
|
Motivo de fin de tratamiento con DMT
|
dmt_stop_reas
|
PV, VS
|
list
|
Razón (atributo)
|
410666004
|
Reacción alérgica
|
|
416093006
|
Anti-JCV Ab positivo / riesgo de PML
|
|
|
Desconocido
|
|
|
Categoría 8. Tratamientos no farmacológicos
|
36
|
P
|
Tratamiento
|
nonph_treat
|
PV, VS
|
list
|
|
|
Terapia ocupacional
|
|
84478008
|
| |
|
|
|
|
|
|
|
Fisioterapia
|
|
91251008
|
| |
|
|
|
|
|
|
|
Psicoterapia
|
|
75516001
|
| |
|
|
|
|
|
|
|
Hidroterapia
|
|
68130003
|
| |
|
|
|
|
|
|
|
Rehabilitación
|
|
52052004
|
| |
|
|
|
|
|
|
|
Fonoterapia
|
|
5154007
|
| |
|
|
|
|
|
|
|
Otra
|
|
|
37
|
P
|
Fecha de inicio
|
nonph_treat_start
|
PV, VS
|
aaa-mm-dd
|
|
413946009
|
|
|
|
38
|
P
|
Fecha de interrupción
|
nonph_treat_stop
|
PV, VS
|
aaaa-mm-dd
|
Día de finalización del tratamiento (entidad observable)
|
413947000
|
|
|
|
Categoría 9. Acceso al sistema de salud y al tratamiento
|
| |
A
|
Seguro de salud
|
seguro_salud
|
PV
|
lista
|
Tipo de seguro o cobertura de salud
|
|
Pública; privada; sin cobertura; desconoce
|
|
|
| |
A
|
Provisión del DMT
|
provisión_tratamiento
|
VS
|
lista
|
Provisión del tratamiento durante el seguimiento por parte de su seguro de salud
|
Sí; no; desconocido
|
|
|
| |
A
|
Cambio de marca de DMT durante el seguimiento
|
cambio_marca_DMT
|
VS
|
lista
|
Cambio de marca del tratamiento por parte de su seguro de salud
|
|
Sí; no; desconocido
|
|
|
EM: esclerosis múltiple; IR: incidencia de recaída; PV: primera visita: VS: visita de seguimiento. a Posibilidad de ser recolectada por: A = ambos; N = neurólogo; P = paciente.
|
 OPEN ACCESS
OPEN ACCESS